Event Period: 05/18 - 06/15
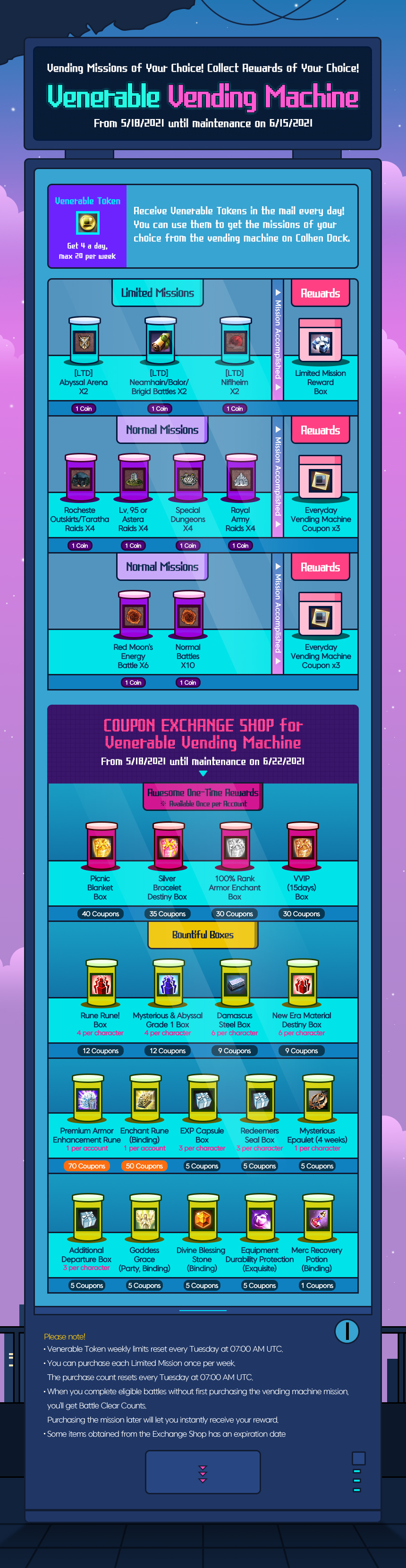
Someone installed a vending machine in Colhen! Check your mail for vending machine tokens!
Event Details
* Per-character event
- Event: The Vending Machine Guide will start for Lv. 30+ characters.
- 20 tokens are distributed on a weekly basis (token distribution resets every Tuesday).
- Use tokens to select and complete missions from the Vending Machine. Each mission gives rewards!
- Venerable Coupons from the mission rewards can be spent in the Exchange Shop.
Mission List
| Goals |
| [LTD] Abyssal Arena |
| [LTD] Neamhain/Balor/Brigid Battles |
| [LTD] Niflheim |
| Rocheste Outskirts/Taratha Raids |
| Lv. 95 or Astera Raids |
| Special Dungeons |
| Royal Army Raids |
| Red Moon's Energy Battle |
| Normal Battles |
* 20 tokens are given per week, for a total of 80 during the event.
* Tokens expire 6/15 at 7 AM UTC.
- Venerable Coupons
- You can obtain a total of 60 Venerable Coupons per week.
- Coupons expire and the Exchange Shop closes on 6/22 at 7 AM UTC
Coupons Awarded per Mission
| Goals | Purchase Limit | Mission Rank | Reward Box | Coupons Awarded | Expiration Date |
| [LTD] Abyssal Arena | Once per week (Resets Tuesdays at 7AM UTC) | Rare | Limited Mission Reward Box | Get 3 from box | 6/22 at 7 AM UTC |
| [LTD] Neamhain/Balor/Brigid Battles | Once per week (Resets Tuesdays at 7AM UTC) | Rare | Limited Mission Reward Box | Get 3 from box | 6/22 at 7 AM UTC |
| [LTD] Niflheim | Once per week (Resets Tuesdays at 7AM UTC) | Rare | Limited Mission Reward Box | Get 3 from box | 6/22 at 7 AM UTC |
| Rocheste Outskirts/Taratha Raids | Unlimited | Superior | Venerable Coupon | 3 | 6/22 at 7 AM UTC |
| Lv. 95 or Astera Raids | Unlimited | Superior | Venerable Coupon | 3 | 6/22 at 7 AM UTC |
| Special Dungeons | Unlimited | Fine | Venerable Coupon | 3 | 6/22 at 7 AM UTC |
| Royal Army Raids | Unlimited | Fine | Venerable Coupon | 3 | 6/22 at 7 AM UTC |
| Red Moon's Energy Battle | Unlimited | Fine | Venerable Coupon | 3 | 6/22 at 7 AM UTC |
| Normal Battles | Unlimited | Regular | Venerable Coupon | 3 | 6/22 at 7 AM UTC |
Exchange Shop
| Item Name | Quantity | Coupon Cost | Tradability | Purchase Limit | Expiration Date |
| Premium Armor Enhancement Rune | 1 | 70 | Bound to Character | 1 per account | 7/13/2021 at 7 AM UTC |
| Enchant Rune (Binding) | 1 | 50 | Bound to Character | 1 per account | 7/13/2021 at 7 AM UTC |
| Picnic Blanket Box | 1 | 40 | Limited Sharing | 1 per account | 7/13/2021 at 7 AM UTC |
| Silver Bracelet Destiny Box | 1 | 35 | Limited Sharing | 1 per account | 7/13/2021 at 7 AM UTC |
| 100% Rank 6 Armor Enchant Box | 1 | 30 | Limited Sharing | 1 per account | 7/13/2021 at 7 AM UTC |
| VVIP (15 Days) Box | 1 | 30 | Limited Sharing | 1 per account | 7/13/2021 at 7 AM UTC |
| Rune Rune! Box | 1 | 12 | Bound to Character | 4 per character | 7/13/2021 at 7 AM UTC |
| Mysterious & Abyssal Grade 1 Box | 1 | 12 | Bound to Character | 4 per character | 7/13/2021 at 7 AM UTC |
| Damascus Steel Box | 1 | 9 | Bound to Character | 6 per character | 7/13/2021 at 7 AM UTC |
| New Era Material Destiny Box | 1 | 9 | Bound to Character | 6 per character | 7/13/2021 at 7 AM UTC |
| Mysterious Epaulet (4 Weeks) | 1 | 5 | Bound to Character | 1 per character | 4 weeks |
| EXP Capsule Box | 1 | 5 | Bound to Character | 3 per character | 7/13/2021 at 7 AM UTC |
| Redeemers Seal Box | 1 | 5 | Bound to Character | 3 per character |
7/13/2021 at 7 AM UTC |
| Additional Departure Box | 1 | 5 | Bound to Character | 3 per character | 7/13/2021 at 7 AM UTC |
| Goddess Grace (Party, Binding) | 1 | 5 | Bound to Character | None | None |
| Divine Blessing Stone (Binding) | 1 | 5 | Bound to Character | None | None |
| Equipment Durability Protection (Exquisite) | 1 | 5 | Bound to Character | None | None |
| Merc Recovery Potion (Binding) | 1 | 1 | Bound to Character | None | None |
Box Contents
Limited Mission Reward Box
- Open to claim all of the following:
| Item Name | Quantity | Tradability | Expiration Date |
| Venerable Coupon | 3 | Bound to Character | 6/22/2021 at 7 AM UTC |
| 2 New Era Materials Box | 1 | Bound to Character | None |
| Goddess Grace (Binding) | 1 | Bound to Character | None |
| Party Merc Recovery Potion (Binding) | 5 | Bound to Character | None |
| Ceara's Fatigue Potion (Binding) | 2 | Bound to Character | None |
2 New Era Materials Box
- Open to claim all of the following:
| Item Name | Quantity | Tradability | Expiration Date |
| New Era Cloth | 2 | Bound to Character | None |
| New Era Leather | 2 | Bound to Character | None |
Picnic Blanket Box
- Open to claim all of the following:
| Item Name | Quantity | Tradability | Expiration Date |
| Picnic Blanket | 1 | Bound to Character | None |
100% Rank 6 Armor Enchant Box
- Open to select and claim one of the following:
| Item Name | Quantity | Tradability |
| Heartless Enchant Scroll | 1 | Bound to Character |
| Weeping Enchant Scroll | 1 | Bound to Character |
| Infinite Enchant Scroll | 1 | Bound to Character |
| Capture Enchant Scroll | 1 | Bound to Character |
| Barrier Enchant Scroll | 1 | Bound to Character |
| Soul Enchant Scroll | 1 | Bound to Character |
VVIP (15 Days) Box
- Open to claim all of the following:
| Item Name | Quantity | Tradability | Expiration Date |
| VVIP Service (15 Days) | 1 | Bound to Character | 7/13/2021 at 7 AM UTC |
Silver Bracelet Destiny Box
- Open to claim all of the following:
| Item Name | Quantity | Tradability | Expiration Date |
| Silver Bracelet | 1 | Bound to Character | None |
| Silver Bracelet | 1 | Bound to Character | None |
Rune Rune! Box
-
Open to claim one of the following. Each item has a different chance to drop:
| Item Name | Quantity | Tradability | Expiration Date |
| Unstable Enhancement Rune (Binding) | 1 | Bound to Character | None |
| Unstable Enchant Rune (Binding) | 1 | Bound to Character | None |
Mysterious & Abyssal Grade 1 Box
- Open to claim all of the following:
| Item Name | Quantity | Tradability | Expiration Date |
| Mysterious Shard Grade 1 | 1 | Bound to Character | None |
| Abyssal Shard Grade 1 | 1 | Bound to Character | None |
Damascus Steel Box
- Open to claim all of the following:
| Item Name | Quantity | Tradability | Expiration Date |
| Damascus Steel (Binding) | 3 | Bound to Character | None |
New Era Material Destiny Box
- Open to select and claim one of the following:
| Item Name | Quantity | Tradability | Expiration Date |
| New Era Cloth | 10 | Bound to Character | None |
| New Era Leather | 10 | Bound to Character | None |
| New Era Ore | 15 | Bound to Character | None |
| New Era Stone | 15 | Bound to Character | None |
| New Era Orb | 15 | Bound to Character | None |
EXP Capsule Box
- Open to claim all of the following:
| Item Name | Quantity | Tradability | Expiration Date |
| EXP 1,000,000 Capsule | 1 | Bound to Character | 7/13/2021 at 7 AM UTC |
| Departure License | 1 | Bound to Character | 7/13/2021 at 7 AM UTC |
Redeemers Seal Box
- Open to claim all of the following:
| Item Name | Quantity | Tradability | Expiration Date |
| Redeemers Seal | 2 | Bound to Character | None |
| Redeemers Departure Strike Ticket | 1 | Bound to Character | 7/13/2021 at 7 AM UTC |
Additional Departure Box
- Open to claim all of the following:
| Item Name | Quantity | Tradability | Expiration Date |
| Departure License | 2 | Bound to Character | 7/13/2021 at 7 AM UTC |
| Divine Blessing Stone (Binding) | 2 | Bound to Character | None |
| Goddess Grace (Binding) | 1 | Bound to Character | None |
Mysterious Epaulet (4 Weeks)
- Epaulet can be used for 4 weeks
- ATT/M. ATT +500 / Critical +2 / Balance +2 / DEF +500 / Counterforce +10